SQL 윈도우함수
윈도우함수 동작원리
등수 부여(순위부여), 부분계산, 등 작업을 도와줄 수 있는것들
-어러가지 작업 분석에 유용하게 활용뒬 수 있는 함수
- 각 window 별 (계산 적용단위) 집합 연산을 수행한 결과를 리턴하는 함수
기본 셀렉트문 처리한 다음 윈도우 함수를처리함
간결한 sql 로 복잡한 분석작업 수행가능
- 다른 함수와 달리 중첩해서 사용 할 수 없음
윈도우 함수 구문

partition by~~~~~~ order by ~~~~ row~~~~
(1) (2) (3)
partition by 를 생략해도 되지만 순서는 꼭 지켜져야 한다
->쓰는 의미는 전체 윈도우함수 분석 할 때 특정 파티션 바이 기준으로 초기화를 시켜줌
ex) partition by deptno 해주면 부서별로 등수 구해줌
(1)을 생략한다면 전체 데이터를 갖고 들어가는것
order by 는 생략 할 수도 있고 못할수도있는데 특정 함수에서는 꼭 지정해야 할때도 있다.
(2)의 역할은 윈도 함수 계산할때 순서대로 정렬해놓고 계산하세요
rows 는 계산 범위를 한정할 때에
어느줄부터 어느줄 까지만 계산에 포함해주세요 하며 지정할 때 사용함
* (1),(2),(3) 은 각각 생략할 수 있지만, 1번만 단독으로 쓰일수 있고, 2번만 단독으로 쓰일 수 있지만 순서 뒤죽박죽은 안되고,
3번 rows 사용할 때는 반드시 order by 를 지정해놓고 사용해야한다(단독사용 안됨)
처리단계

**where, group by, having 윈도우 함수 사용할 수 없다.
윈도우 함수 종류
RANK
누가1등이고 2등일지 기준은 order by 절에 붙여줘야 한다.
ex)입사먼저 한 사람 = order by hiredate,
partition by 지정했다면 각 파티션 별로 따로 순위가 매겨진다.
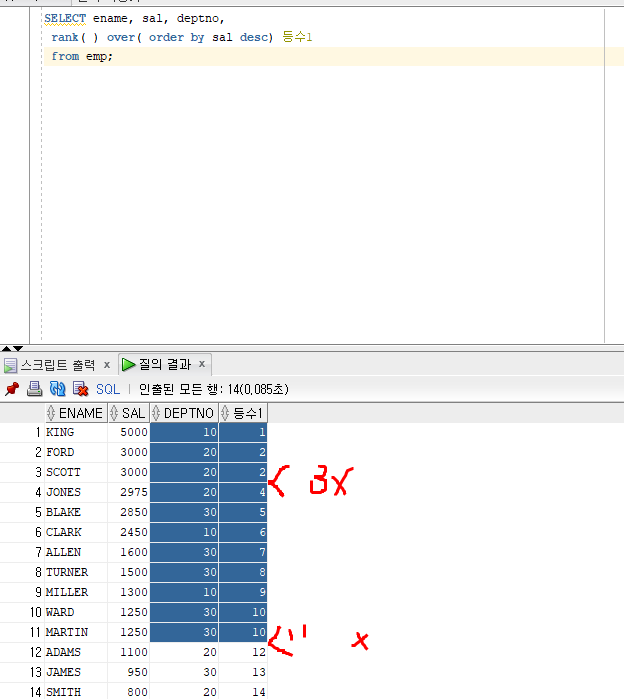
*사원번호, 이름 , 부서번호, 급여, 급여가 많은 사원부터 순위조회
select empno ename, deptno, sal,
RANK( ) over(ORDER BY sal DESC) "RANK" [over 뒤에 어떤 애 1등으로 해주세요 하는 설명]
from emp;
*사원번호 , 이름, 부서번호, 급여, 부서 내에서 급여가 많은 사원부터 순위조회
select empno, ename, deptno, sal,
RANK( ) over
(PARTITION BY deptno ORDER BY sal DESC)"RANK"
from emp;
DENSE_RANK
rank 함수와 차이=등수 부여할때 시험점수로 할 때 100점이 2명 그다음 99점,
이때 rank 함수 쓰면 100점 두명이 둘다 1등, 99점을 3등으로 부여함,
dense_rank 함수로 쓰면, 100점 두명을 1등으로 표시하지만 99점은 2등으로 (순위에 1등 다음은 2등으로 몇명이 들어가든 표시가 됨)

*사원번호, 이름, 부서번호, 급여, 급여가 많은 사원부터 순위조회
select empno, ename, deptno, sal,
DENSE_RANK( ) over(ORDER BY sal DESC) "DRANK"
from emp;
*사원번호 , 이름, 부서번호, 급여, 부서 내에서 급여가 많은 사원부터 순위조회
select empno, ename, deptno, sal,
DENSE_RANK( ) over
(PARTITION BY deptno ORDER BY sal DESC)"RANK"
from emp;

ROW_NUMBER
전부다 다른 번호 값을 부여하는것 100점이 10명이라도 한명은 1번 다른사람은 2번 3번 이런식으로 부여됨
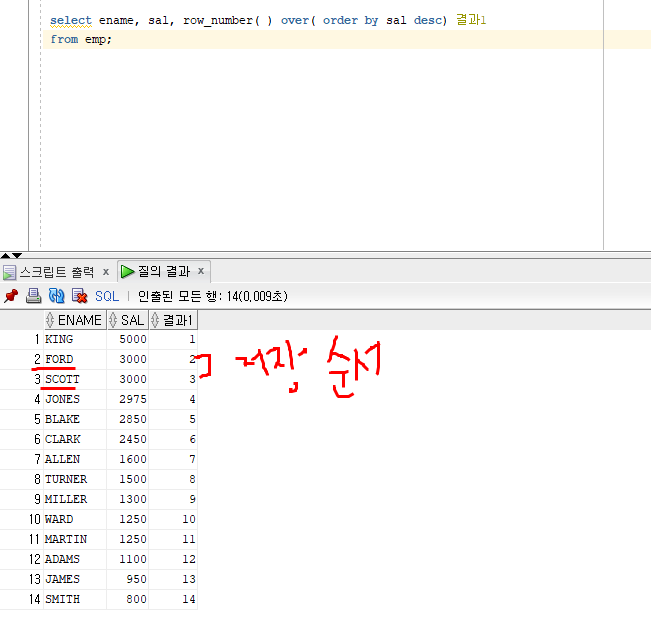
*사원번호, 이름, 부서번호, 급여, 급여가 많은 사원부터 순위조회
select empno, ename, deptno, sal,
ROW_NUMBER( ) over (ORDER BY sal DESC)"DRANK" [연봉이 높은값부터 나오는데 번호를 다 부여해줘]
from emp;
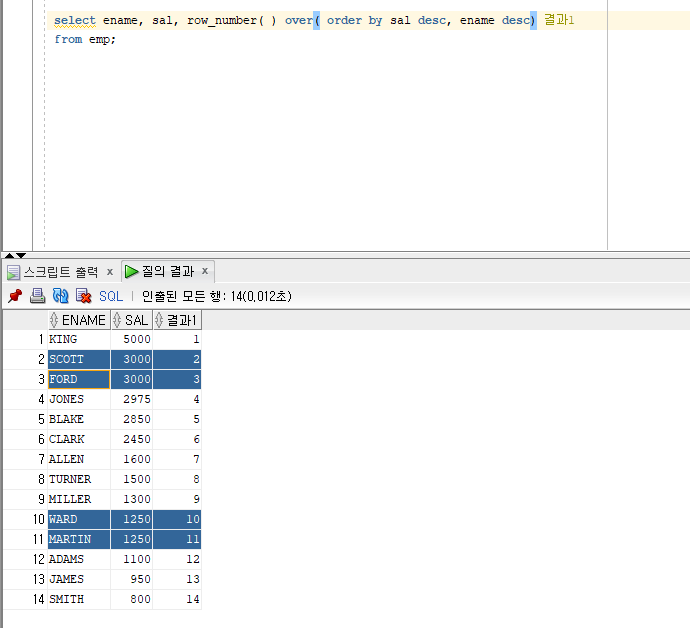
*사원번호, 이름, 연봉, 입사일, 순번조회(급여가 많은순으로, 같은 급여를 받는 경우 입사일이 빠른 사람부터 앞번호 부여)
select empno, ename, sal, hiredate,
ROW_NUMBER( ) over
(ORDER BY sal DESC , hiredate asc) AS"순번" [급여가 많은 애부터 부여하는데 같은 애들이 두명이면 두번재 값으로 비교해줘 -> 조건두개를 정렬 했을 때 앞의 값이 같으면 뒤의 값으로 정렬 해줘=연봉이 같으면, 입사일 빠른사람부터 해줘]
from emp;
NTILE
데이터 사용량에 따라 15개 그룹으로 나눠서 얼마나 사용하는지 보고싶을때
특정값 기준으로 분류해서 1그룹 부터 N 그룹까지 나타내는것
-만약 103개의 row 에 대해서 ntile(5)를 적용하면 첫번째 bucket 부터 세번째 까지는 21개의 row 가, 나머지는 20개의 row 가 배치됨
NTILE( 나누고 싶은 그룹 개수 숫자)
*급여가 적은 사원부터 4개로 분류해서 조회
select ename, sal ,NTILE($) over (order by sal)
from emp;

Window aggregate family
*사원이름, 부서번호, 급여, 전체급여 합계, 부서별 급여 합계조회
select ename, deptno, sal,
SUM(sal)over( ) "total_sum" [over 가 붙어서 sum 과 같은 그룹함수(직계함수)도, 분석함수로 사용할 수 있다= over 가 있으면 분석함수로본다]=>급여합계
SUM(sal) over (partition BY deptno)"dept_sum"
from emp;
_ROWS 옵션을 사용해서 윈도우 함수계산 범위를 지정함

sum (sal) 계산을 할때 rows 옵션이 없으면 전체 범위에서 계산이 되는데 rows 를 붙이기 위해 order by 가 나와야한다.
sal 순으로 정렬해둔 다음에 내 데이터 기준으로 한줄 앞에 나오는 데이터 부터 한줄 다음의 데이터 까지 더해주세요
LAG
앞에 있는것 끌어내릴 때
LAG(sal,1,0) => 나는 1줄 앞에 있는 sal 의 값을 갖고 올게요, 한줄앞에 sal 이 없으면 0 으로 표시할게요
LAG(sal,1, sal )=> 나는 1줄 앞에 있는 sal 의 값을 갖고 올게요, 한줄앞에 sal 이 없으면 그냥 내급여 그대로 sal 값으로 쓸게

LEAD
뒷줄에 나온 데이터를 끌어올릴때 사용
LEAD(sal, 1, 0) -> 나는 1줄 뒤에 있는 sal 의 값을 갖고오는데 없으면 0으로 쓸게요